首先当然是最难的,在获取文章分类中的列表时,请求体中的sign值有加密分析用户请求获取文章目录下的所有文章列表进入用户界面后点击相应的文章分类→自动驾驶,请求方式为带参数的get请求,分析请求体,发现sign...

首先当然是最难的,在获取文章分类中的列表时,请求体中的sign值有加密
分析用户请求
获取文章目录下的所有文章列表
进入用户界面后点击相应的文章分类→自动驾驶,请求方式为带参数的get请求,分析请求体,发现sign参数为加密参数,点击不同的分类时sign参数发生变化
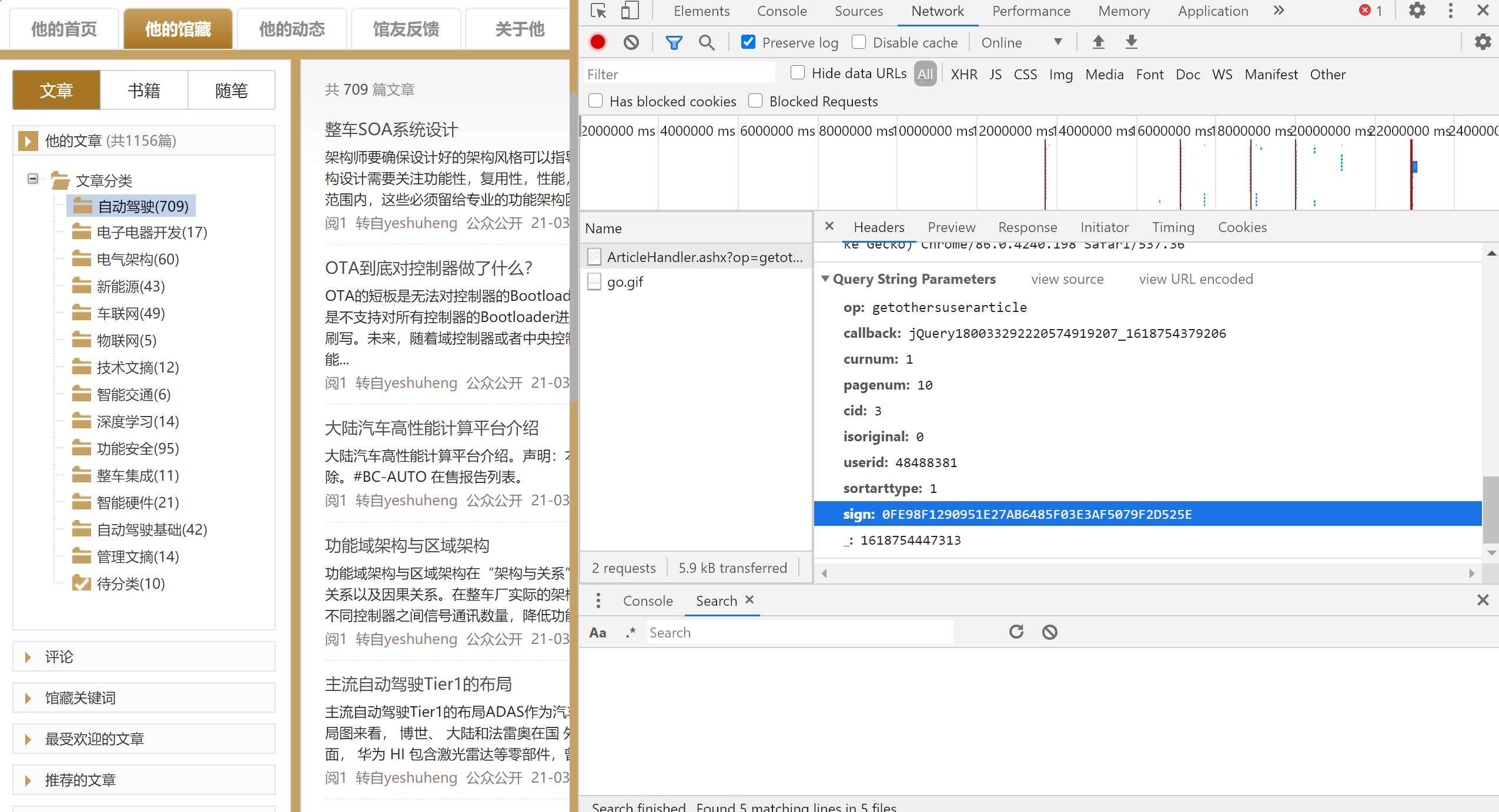
在sources界面进行全局搜索请求url中的关键字 ‘ArticleHandler’ 得到以下结果
该js为eval(function()){}()直接执行函数生成返回值
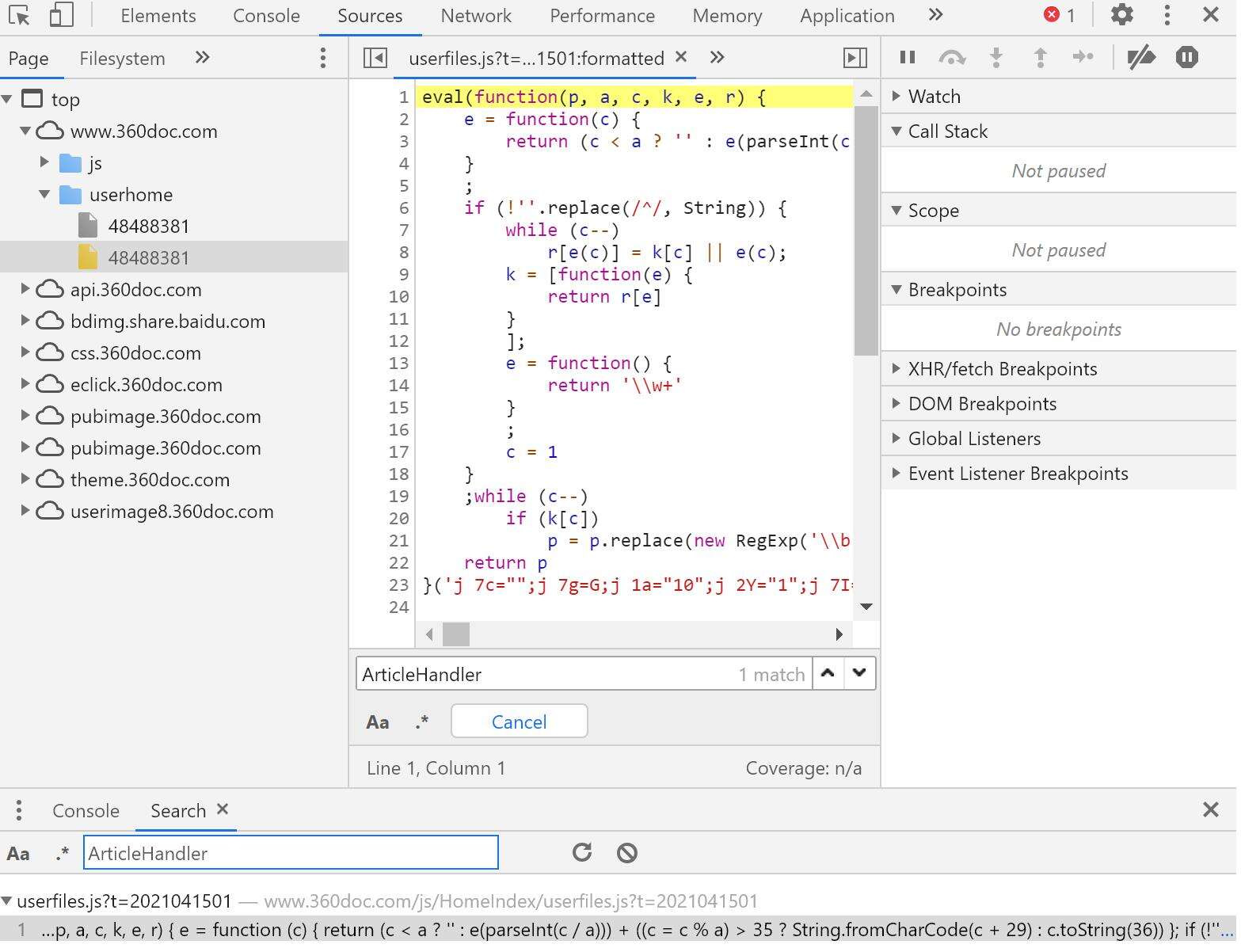
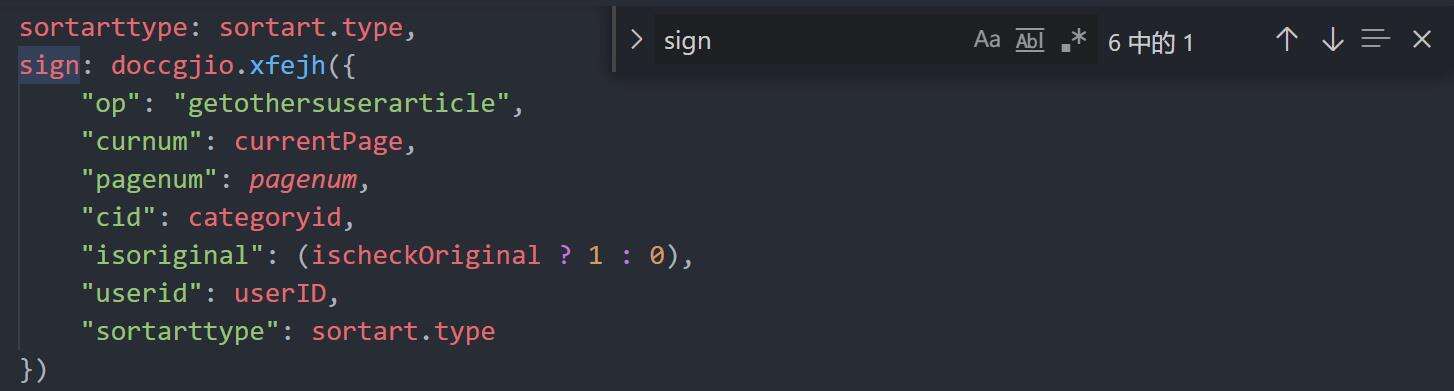
复制该函数至console中直接执行,得到返回值p,p为js代码,保存到本地后搜索关键字 ‘sign’,得到以下结果,其中json中的各项参数与请求体中的参数一致,表明sign是通过此处 ‘doccgjio.xfejh’ 加密实现
接着全局搜索 ‘doccgjio' 后发现doccgjio.js为所有加密算法处理文件
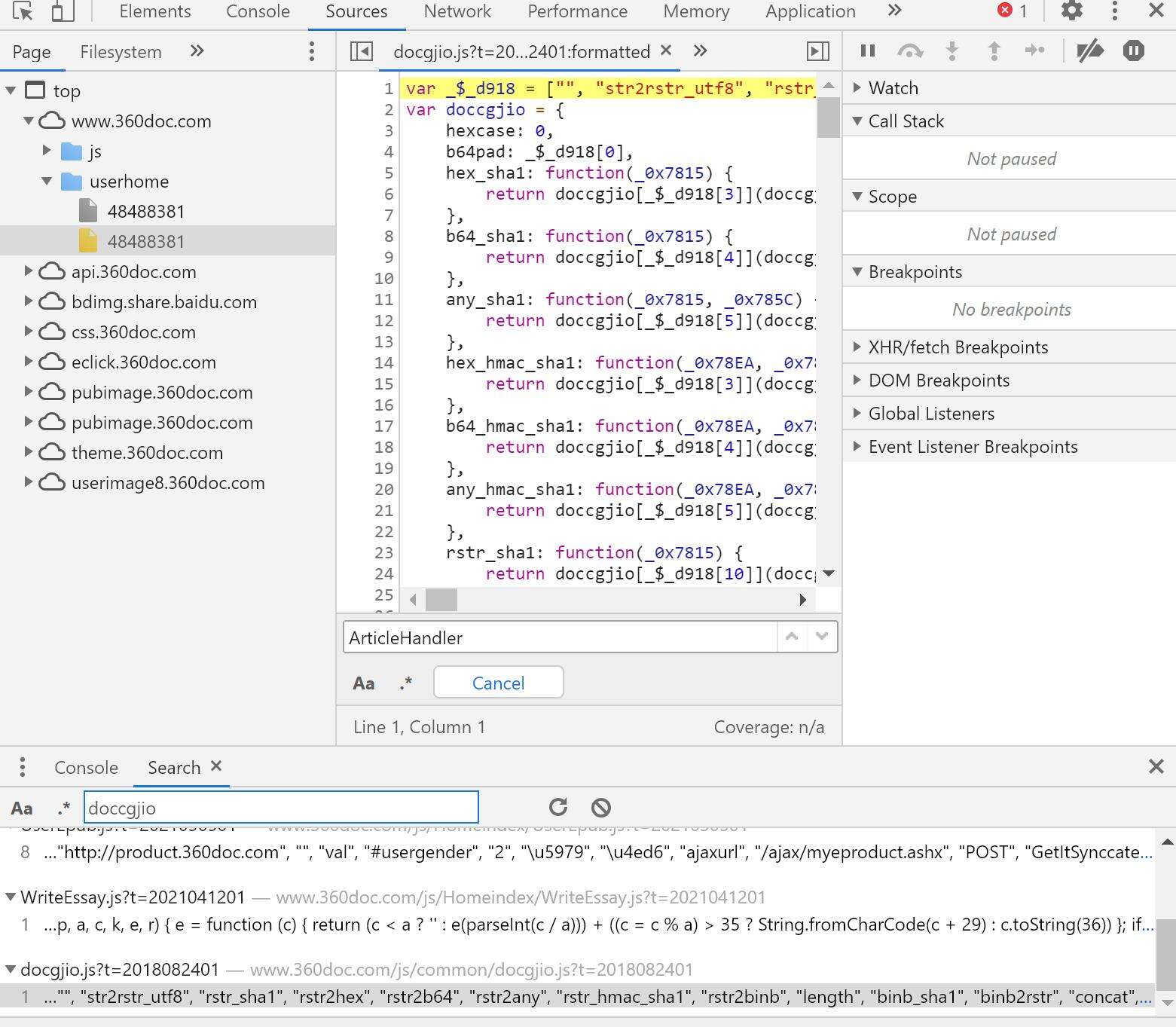
接着在将js中代码放进console中执行,并调用doccgjio.xfejh( ),得到的sign值与请求体中的一致,结束,接下来就可以使用PyExecJS库进行处理生成sign值

下面附上全部代码,用的都是常规库,目前还有点问题
- 跑一段时间会封ip,有兴趣的可以加上随机代理
- 为了不给服务器太大压力,没用多线程,并且加入了sleep,跑的比较慢,可以加上多线程跑
import time
import re
import os
import requests
import json
import execjs
import math
import random
from urllib.parse import unquote
from requests_html import HTMLSession
def get_art_cate(userid, url, headers, cur_time): # 获取文章分类
params = {'type': 3, 'userid': userid, '-': cur_time}
req = requests.get(url, headers=headers, params=params)
# 对响应信息进行urldecode并去除多余信息
cate_list = unquote(req.content)[1:len(unquote(req.content)) - 3]
# 将str中字典提取进列表
cate_list = re.findall(r'{ id.*?"}', cate_list)
for i in range(len(cate_list)):
# 去除多余字符串,方便转为字典
cate_list[i] = cate_list[i].replace('"', '').replace(
' ', '').strip('{').strip('}')
# print(cate_list[i])
# 将字符串转为字典,方便后续取值
cate_list[i] = {
n.split(':')[0]: n.split(':')[1]
for n in cate_list[i].split(',')
}
# print(cate_list[i])
return cate_list
def get_art_list(userid, url, headers, cur_time, cid,
artnum): # 获取文章某个分类下的所有文章列表
artnum = math.ceil(int(artnum) / 10)
for i in range(1, artnum + 1):
time.sleep(random.random())
sign = gen_sign(userid, cid, i)
params = {
'op': 'getothersuserarticle',
'curnum': i,
'pagenum': '10',
'cid': cid,
'isoriginal': '0',
'userid': userid,
'sortarttype': '1',
'sign': sign,
'_': cur_time
}
req = requests.get(url, headers=headers, params=params)
# print(json.loads(unquote(req.content)))
for i in json.loads(unquote(req.content))['listitem']:
time.sleep(random.random())
yield i['arturl']
def save_html(url, headers, target_dir): # 保存网页到本地
session = HTMLSession()
req = session.get(url, headers=headers)
#取出文章所在的位置,为列表,first=ture提取第一个
content = req.html.find('#articlecontent', first=True)
#取出文章标题
art_name = req.html.xpath('//*[@id="titiletext"]/text()', first=True)
#替换标题中的非法字符,生成文件夹的时候出错
rstr = r"[\/\\\:\*\?\"\<\>\|]" # '/ \ : * ? " < > |'
art_name = re.sub(rstr, "_", str(art_name))
#目标存储路径
target_dir = target_dir
#根据文章标题创建文件夹
art_dir_path = os.path.join(target_dir, art_name)
#然后根据文件夹创建相应的html文件
art_path = os.path.join(art_dir_path, art_name + '.html')
os.makedirs(art_dir_path, exist_ok=True)
img_list = req.html.xpath('//img[contains(@src,"image109")]/@src')
html_str = content.html
for img_url in img_list: #获取文章中的所有图片的连接
save_img(headers, img_url, art_dir_path)
if re.search(img_url, content.html): #匹配url并替换为本地图片地址
new_img_url = img_url.split('/')[-1] + '.jpg'
#str是常量需重新赋值才行
html_str = html_str.replace(img_url, new_img_url)
with open(art_path, 'w', encoding='utf-8') as f:
f.write(html_str) # 此处如果使用requests-html中css选择器将文章部分保存为html,图片无法加载
def save_img(headers, url, dir_path): # 将html中图片保存到本地
req = requests.get(url, headers=headers)
img_path = os.path.join(dir_path, url.split('/')[-1]+ '.jpg')
with open(img_path, 'wb') as f:
f.write(req.content)
def gen_sign(userid, cid, curnum): # 利用excejs执行本地js文件
x = {
"op": "getothersuserarticle",
"curnum": curnum,
"pagenum": 10,
"cid": cid,
"isoriginal": 0,
"userid": userid,
"sortarttype": 1
}
with open(r'D:\WorkSpace\Python\Test\360Doc\encrypt_method.js',
encoding='utf-8') as f:
js_data = f.read()
c = execjs.compile(js_data)
code = "wlht2019({})".format(x) #wlht2019是文件中的某个函数,x是传入的参数
sign = c.eval(code)
return sign
def main(userid):
cur_path = os.path.split(os.path.realpath(__file__))[0]
cate_url = 'http://www.360doc.com/ajax/getmyCategory.ashx'
art_url = 'https://api.360doc.com/Ajax/ArticleHandler.ashx'
cur_time = str(time.time() * 1000).split('.')[0]
useragent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.128 Safari/537.36 Edg/89.0.774.77'
headers1 = {
'User-Agent': useragent,
'Referer': 'http://www.360doc.com/userhome.aspx?userid=' + str(userid)
}
headers2 = {'User-Agent': useragent, 'Referer': 'http://www.360doc.com'}
cate_list = get_art_cate(userid, cate_url, headers1, cur_time)
for i in cate_list[1:]:
cate_path = os.path.join(cur_path, i['selftitle'])
os.makedirs(cate_path, exist_ok=True)
art_list = get_art_list(userid, art_url, headers2, cur_time, i['id'], i['artnum'])
for j in range(int(i['artnum'])+1):
try:
x = next(art_list)
print('before '+x)
save_html(x, headers2, cate_path)
except:
pass
continue
if __name__ == "__main__":
userid = 48488381
main(userid)
沃梦达教程
本文标题为:爬取360Doc用户馆藏存为html-包括js解密


猜你喜欢
- 使用AngularJS2中的指令实现按钮的切换效果 2022-07-07
- 浅谈由position属性引申的css进阶讨论 2022-11-20
- html代码高亮highlight.js插件的使用,如何使用highlight.js高亮代码 2023-08-29
- ajax异步读取后台传递回的下拉选项的值方法 2023-02-23
- html+css实现分层金字塔的实例 2022-09-20
- vue3.0之Teleport 2023-10-08
- 学习笔记(二)主要是一些HTML的标签学习 2023-10-27
- 通过history解决ajax不支持前进/后退/刷新的问题 2023-02-14
- webpack高级配置与优化详解 2022-11-13
- HTML5实现桌面通知 提示功能 2022-09-16