Apache Spark 2.4 回顾以及 3.0 展望过往记忆大数据 过往记忆大数据 本文资料来自 2019-03-28 在旧金山举办的 Strata Data Conference,详情请参见 https://conferences.oreilly.com/strata/strata-ca/public/sche...

Apache Spark 2.4 回顾以及 3.0 展望
过往记忆大数据 过往记忆大数据
本文资料来自 2019-03-28 在旧金山举办的 Strata Data Conference,详情请参见 https://conferences.oreilly.com/strata/strata-ca/public/schedule/detail/72637。分享者来自数砖著名的范文臣和李潇两位大佬。
本次分享包括了对 Apache Spark 2.4 回顾以及对 Apache Spark 3.0 的展望。Apache Spark 2.4 版本是 2.x 系列的第五个版本,此版本的主要特性包括以下几点:
- 新的调度模型(Barrier Scheduling),使用户能够将分布式深度学习训练恰当地嵌入到 Spark 的 stage 中,以简化分布式训练工作流程。
- 添加了35个高阶函数,用于在 Spark SQL 中操作数组/map。
- 新增一个新的基于 Databricks 的 spark-avro 模块的原生 AVRO 数据源。
- PySpark 还为教学和可调试性的所有操作引入了热切的评估模式(eager evaluation mode)。
- Spark on K8S 支持 PySpark 和 R ,支持客户端模式(client-mode)。
- Structured Streaming 的各种增强功能。 例如,连续处理(continuous processing)中的有状态操作符。
- 内置数据源的各种性能改进。 例如,Parquet 嵌套模式修剪(schema pruning)。
- 支持 Scala 2.12。
更多关于 Apache Spark 2.4 的东西请参见《Apache Spark 2.4 正式发布,重要功能详细介绍》。
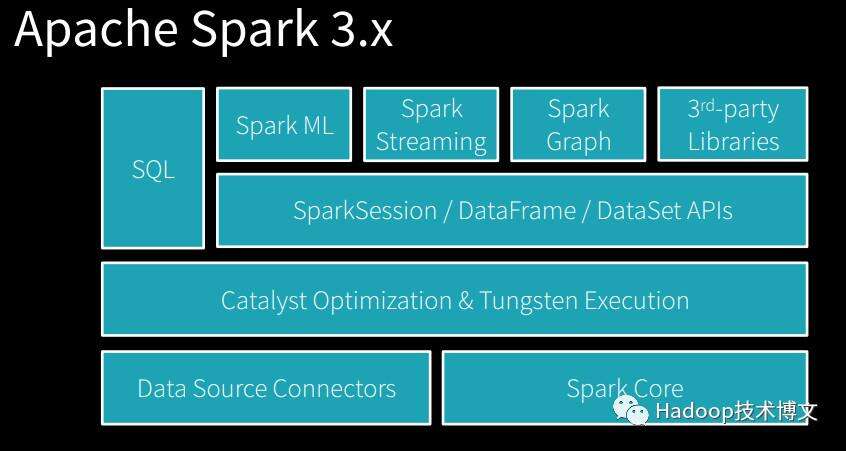
Apache Spark 3.0 也包含了许多重要的特性,比如 GPU 感知调度(GPU-aware Scheduling,详细请参见 《Apache Spark 3.0 将内置支持 GPU 调度,文末有福利》) 、Spark Graph 图的增强、Data Source API V2、自适应执行(Adaptive Execution,详细请参见《Adaptive Execution如何让Spark SQL更高效更好用?》、Apache Spark SQL自适应执行实践https://www.iteblog.com/archives/2319.html)、 支持 Hadoop 3.x、支持 Hive 2.3.4、Scala 2.12 GA、更好的ANSI SQL合规性、PySpark 可用性进一步提升等。当然,这仅仅是简单地介绍了 Apache Spark 3.0 的特性,冠以 Spark 3.0 更详细的介绍请参见04月23-25日在旧金山举办的Spark+AI Summit 2019!,下图是 Apache Spark 3.x 的新架构图。
好了,废话不多说了,下面是本次会议的PPT全文,关注 Hadoop技术博文 公众号,并回复 spark-3 获取本文PPT。






沃梦达教程
本文标题为:Apache Spark 2.4 回顾以及 3.0 展望


猜你喜欢
- nginx中封禁ip和允许内网ip访问的实现示例 2022-09-23
- 阿里云ECS排查CPU数据分析 2022-10-06
- CentOS7安装GlusterFS集群的全过程 2022-10-10
- 【转载】CentOS安装Tomcat 2023-09-24
- 利用Docker 运行 python 简单程序 2022-10-16
- CentOS_mini下安装docker 之 安装docker CE 2023-09-23
- 教你在docker 中搭建 PHP8 + Apache 环境的过程 2022-10-06
- IIS搭建ftp服务器的详细教程 2022-11-15
- KVM虚拟化Linux Bridge环境部署的方法步骤 2023-07-11
- 解决:apache24 安装后闪退和配置端口映射和连接超时设置 2023-09-11