sql跨表查询的三种方案总结 目录 前言 方案一:连接多个库,同步执行查询 优点 缺点 代码执行 方案二:在主数据库增加冗余表,通过定时更新,造成同库联表查询 优点 缺点 相似实现场景 方案三:dbLink本地连接多个库,在本地进行数据分析 优点 缺点 前
目录
- 前言
- 方案一:连接多个库,同步执行查询
- 优点
- 缺点
- 代码执行
- 方案二:在主数据库增加冗余表,通过定时更新,造成同库联表查询
- 优点
- 缺点
- 相似实现场景
- 方案三:dbLink本地连接多个库,在本地进行数据分析
- 优点
- 缺点
前言
最近又个朋友问我,如何进行sql的跨库关联查询? 首先呢,我们知道mysql是不支持跨库连接的,但是老话说得好,只要思想不滑坡,思想总比困难多!
PS: 问题摆在这里了,还能不解决是怎么的?
经过一番思考我给他提出了三个方案,虽然都不尽善尽美,但各领风骚!
连接方案,以postgreSql库为例。
方案一:连接多个库,同步执行查询
具体思路为在代码中分别连接多个库,查到一个库中所需要的数据之后,通过关键字段,同步执行去其他的库中进行查询相关数据,然后进行需要的数据分析或更新!
优点
- 可以进行实时查询;
- 可对数据进行按需修改及逻辑范围内的修改返回值;
- 一般采用此方案,查询数据会分页查询,或查询条件精确,从而量会比较小,对服务器压力小;
- 服务器静态分析数据,效率高;
缺点
- 不适合进行大批数据写入/查询,会造成数据库连接超时或获取的数据流过大导致服务器内存被大量占用;
- 同步执行策略,查询数据库用时和运行时间成正比;
代码执行
一些简单的代码逻辑,不会有人看不懂吧~~~
postgreSql.js
//链接多个数据库,并暴露
const pg = require('pg');
const sqlConfig = {
testOnePgSql: {
user: "postgres",
database: "admindb",
password: "123",
host: "192.168.1.111",//数据库ip地址(胡乱写的,写自己的库ip哈)
port: 5432, // 扩展属性
max: 20, // 连接池最大连接数
idleTimeoutMillis: 3000
},
//超岛商户
testTwoPgSql: {
//测试数据库
user: "postgres",
database: "admindb",
password: "123",
host: "192.168.1.112",//数据库ip地址(胡乱写的,写自己的库ip哈)
port: 5432, // 扩展属性
max: 20, // 连接池最大连接数
idleTimeoutMillis: 3000
},
//桃娘商户
testThreePgSql: {
//测试数据库
user: "postgres",
database: "admindb",
password: "123",
host: "192.168.1.113",//数据库ip地址(胡乱写的,写自己的库ip哈)
port: 5432, // 扩展属性
max: 20, // 连接池最大连接数
idleTimeoutMillis: 3000
},
};
const testOnePgSql = new pg.Pool(sqlConfig.banuPgSql);
const testTwoPgSql = new pg.Pool(sqlConfig.testTwoPgSql);
const testThreePgSql = new pg.Pool(sqlConfig.testThreePgSql);
module.exports = {
testOnePgSql,
testTwoPgSql,
testThreePgSql
};封装查询pgsql方法
postgreSqlClass.js
let sqlMap = require('./postgreSql');
module.exports = {
/**
*查询pgsql数据
* @param sqlSelect 查询语句 string
* @param tenancy 商户id string
*/
select(sqlSelect, tenancy) {
//按需连接
let pool = sqlMap[tenancy];
return new Promise((resolve, reject) => {
pool.connect(async function (err, connection) {
if (err) {
// 结束会话
connection.release();
return reject(err);
}
let result = await pgQuery(sqlSelect, connection);
// 结束会话
connection.release();
return resolve(result);
});
});
}
};
/**
* pgsql查询数据
* @param sqlQuery 查询语句
* @param connection pgSql连接后的connection
* @returns {Promise<unknown>}
*/
async function pgQuery(sqlQuery, connection) {
return new Promise((resolve, reject) => {
connection.query(sqlQuery, (err, rows) => {
if (err) return reject(err);
return resolve(rows.rows || []);
});
});
}现在进行业务模块
test.js
"use strict";
//引入pg函数
let PGSQL = require("./postgreSqlClass");
exports.getUserList = async () => {
let sqlOneSelect = `${第一个表查询语句}`;
let userList = await PGSQL.select(sqlSelect, "testOnePgSql");
//获取对应two表的数据
//...逻辑
let sqlTwoSelect = `${第一个表查询语句}`;
let userListTwo = await PGSQL.select(sqlTwoSelect, "testTwoPgSql");
let result = [];
//组合你想要的数据
//...逻辑
return result;
};方案二:在主数据库增加冗余表,通过定时更新,造成同库联表查询
比如A库为主数据库,B、C为其他的增项库,我们需要将三个库中的user表进行数据联表查询; 具体思路为:
- 在A库存在user表,此时创建冗余表user_two、user_three表,并字段对应B、C库的user表字段;
- 通过代码逻辑,进行定时任务,将B、C表,数据更新至A库user_two、user_three表;
- 在需要数据分析/查询时,仅查询A库即可,但需要将A库的user、user_two、user_three表进行按需取用;
优点
- 化跨表查询为同表查询,执行逻辑更为简单;
- 可进行大数据分析和大数据查询;
- 可以预处理数据,提高分析速率;
缺点
- 定时更新,不具备及时性;
- 需要对应表有最后更新时间字段,否则同步数据会比较多;
- 增加冗余表,会造成主表空间占用率增加;
- 定时更新,会导致某一时间点有大量数据写入/修改数据,可能会影响数据读取,因此,建议多节点部署(读写、只读);
相似实现场景
- T+1时间的报表展示;
- 局域网本地数据库信息上报至线上数据库;
方案三:dbLink本地连接多个库,在本地进行数据分析
(极度不建议)
具体思路:
- dblink就是我们在创建表的时候连接到我们的远程库,然后我们本地新建的表数据就是映射远程的表的数据。
- 当我们创建一个以FEDERATED为存储引擎的表时,服务器在数据库目录只创建一个表定义文件。文件由表的名字开始,并有一个frm扩展名。无其它文件被创建,因为实际的数据在一个远程数据库上。这不同于为本地表工作的存储引擎的方式。
执行步骤:
- 1.如我现在本地要连接我的阿里云的sys_user表,所以我需要在本地建一个相同字段的表,我取名叫sys_user_copy,并连接到远程库,建好后,我本地sys_user_copy的表里面的数据是映射远程的表的数据
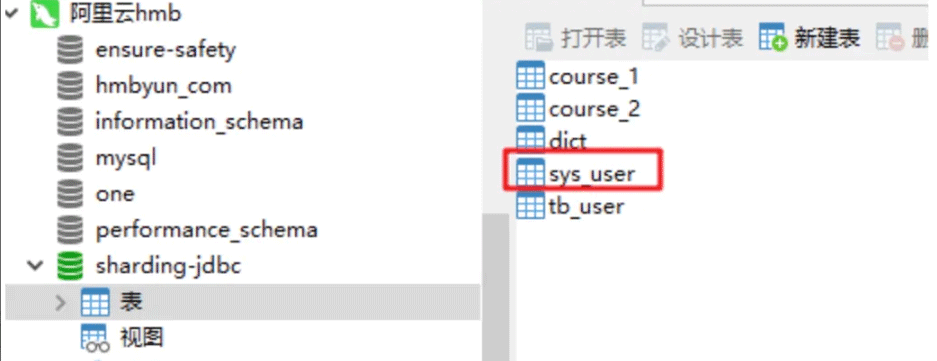

- 2.所以我关联查询,可以直接关联我本地sys_user_copy表从而查出来。改了本地的数据,远程的表数据也会跟着变
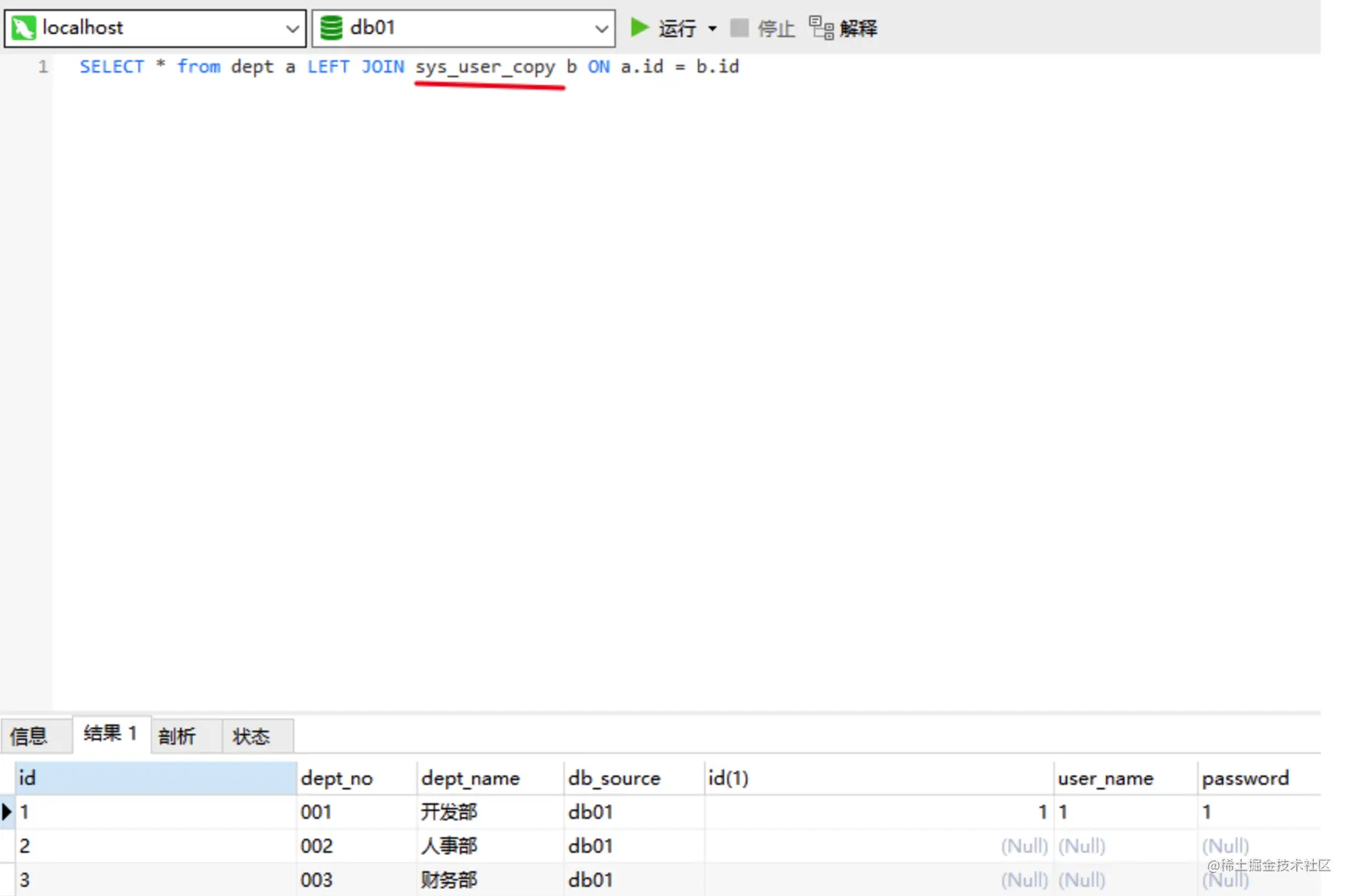

**开启FEDERATED引擎,**show engines
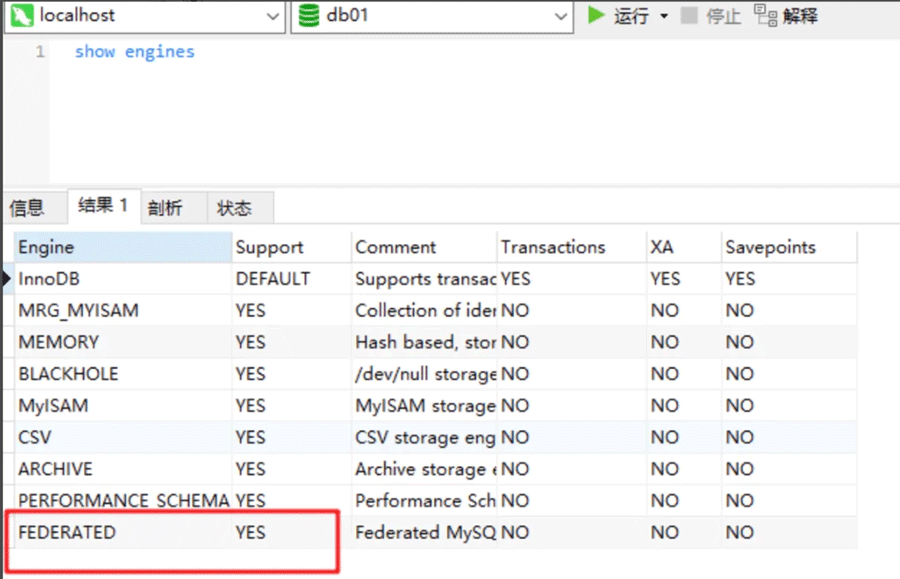
如果这里是NO,需要在配置文件[mysqld]中加入一行:federated
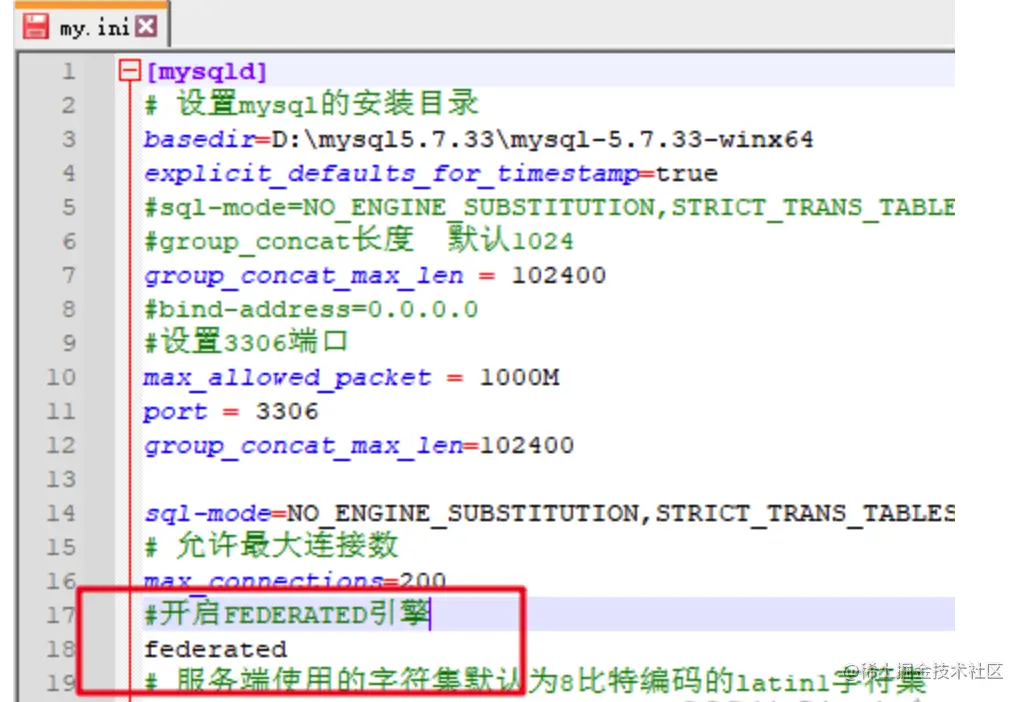
改完重启服务,就变成yes了。
- 4 建表时加上连接

CREATE TABLE (......)
ENGINE =FEDERATED CONNECTION='mysql://username:password@hostname:port/database/tablename'优点
- 不需要程序员介入,不需要开发
- 快速形成结果,如果只想查询一些数据的话
缺点
- 本地表结构必须与远程表完全一样
- 不支持事务
- 不支持表结构修改
- 删除本地表,远程表不会删除
- 远程服务器必须是一个MySQL服务器
- 并不会在本地写入数据库数据,实质上是一个软连接,查询大量数据会导致本地内存爆满,因为是查询多个数据库的数据到本地内存,然后在内存中进行计算,此时时间复杂度为O(N^2),空间复杂度也为O(N^2);500条数据,对应本地时间复杂度为25W,时间复杂度为25W;
可用于:两库之间数据导入,不涉及计算,即A导入B,不进行查询A\B进行计算写入C;
到此这篇关于sql跨表查询的三种方案总结的文章就介绍到这了,更多相关sql跨表查询 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
沃梦达教程
本文标题为:sql跨表查询的三种方案总结


猜你喜欢
- Oracle 删除大量表记录操作分析总结 2023-07-23
- 在阿里云CentOS 6.8上安装Redis 2023-09-12
- 基于Python制作一个简单的文章搜索工具 2023-07-28
- SQLSERVER调用C#的代码实现 2023-07-29
- Mongodb启动报错完美解决方案:about to fork child process,waiting until server is ready for connections. 2023-07-16
- 搭建单机Redis缓存服务的实现 2023-07-13
- MySQL8.0.28安装教程详细图解(windows 64位) 2023-07-26
- SQL Server 2022 AlwaysOn新特性之包含可用性组详解 2023-07-29
- Numpy中如何创建矩阵并等间隔抽取数据 2023-07-28
- redis清除数据 2023-09-13








