使用MySQL的Explain执行计划的方法(SQL性能调优) 目录 前言 1. explain的使用 2. explain字段详解 id列 select_type列 table列 partitions列 type列 system const eq_ref ref ref_or_null index_merge range index ALL possible_keys列 key列 key_len列 ref列 rows列 filtered列 Extra列 Using where Using
目录
- 前言
- 1. explain的使用
- 2. explain字段详解
- id列
- select_type列
- table列
- partitions列
- type列
- system
- const
- eq_ref
- ref
- ref_or_null
- index_merge
- range
- index
- ALL
- possible_keys列
- key列
- key_len列
- ref列
- rows列
- filtered列
- Extra列
- Using where
- Using index
- Using filesort
- Using temporary
- Using join buffer
- Using index condition
- 知识点总结
前言
上篇文章讲了MySQL架构体系,了解到MySQL Server端的优化器可以生成Explain执行计划,而执行计划可以帮助我们分析SQL语句性能瓶颈,优化SQL查询逻辑,今天就一块学习Explain执行计划的具体用法。
1. explain的使用
使用EXPLAIN关键字可以模拟优化器执行SQL语句,分析你的查询语句或是结构的性能瓶颈。 在 select 语句之前增加 explain 关键字,MySQL 会在查询上设置一个标记,执行查询会返回执行计划的信息,并不会执行这条SQL。
就比如下面这个:

输出这么多列都是干嘛用的?
其实大都是SQL语句的性能统计指标,先简单总结一下每一列的大致作用,下面详细讲一下:

2. explain字段详解
下面就详细讲一下每一列的具体作用。
id列
id表示查询语句的序号,自动分配,顺序递增,值越大,执行优先级越高。

id相同时,优先级由上而下:
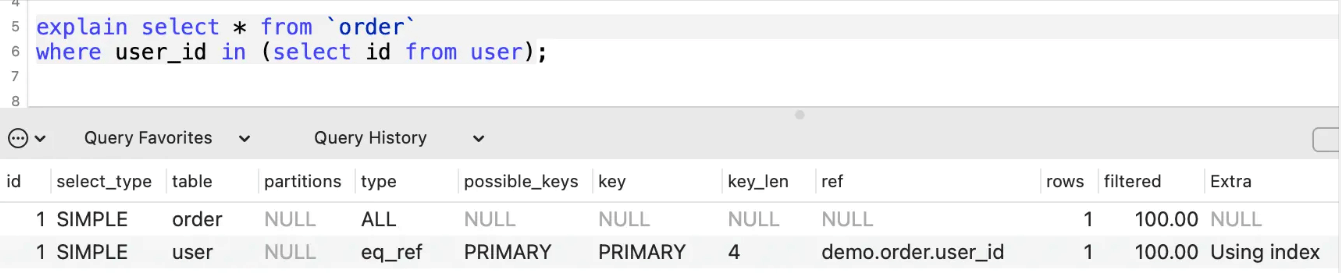
select_type列
select_type表示查询类型,常见的有SIMPLE简单查询、PRIMARY主查询、SUBQUERY子查询、UNION联合查询、UNION RESULT联合临时表结果等。
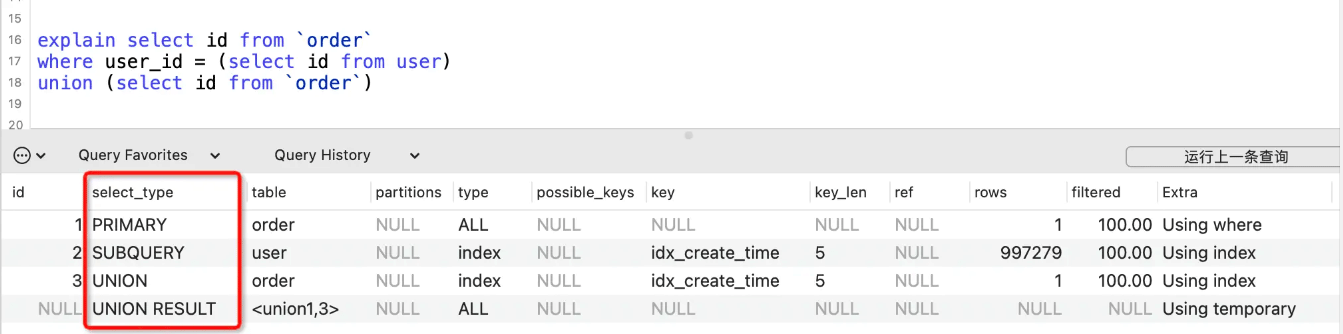
table列
table表示SQL语句查询的表名、表别名、临时表名。
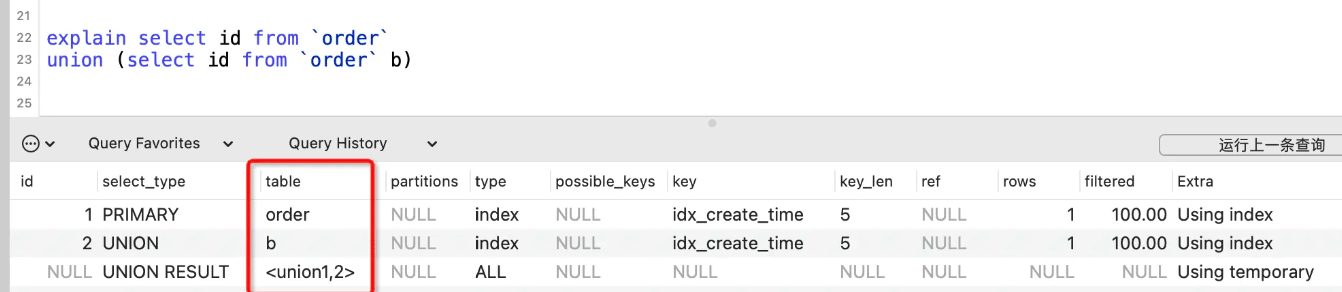
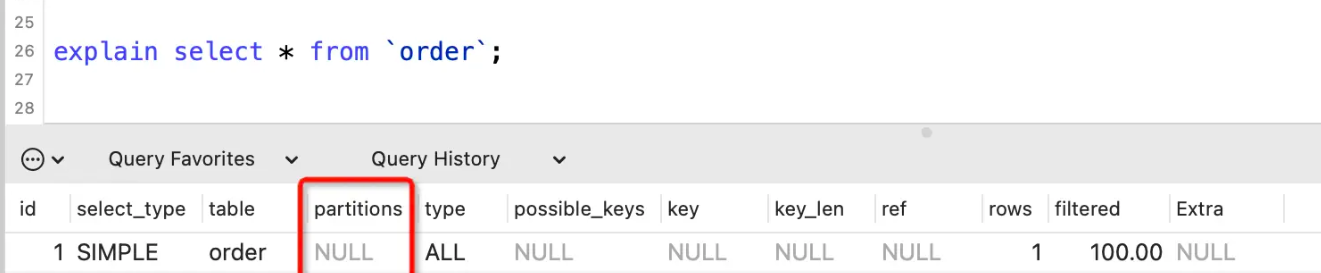
partitions列
partitions表示SQL查询匹配到的分区,没有分区的话显示NULL。
type列
type表示表连接类型或者数据访问类型,就是表之间通过什么方式建立连接的,或者通过什么方式访问到数据的。
具体有以下值,性能由好到差依次是:
system > const > eq_ref > ref > ref_or_null > index_merge > range > index > ALL
system
当表中只有一行记录,也就是系统表,是 const 类型的特列。

const
表示使用主键或者唯一性索引进行等值查询,最多返回一条记录。性能较好,推荐使用。

eq_ref
表示表连接使用到了主键或者唯一性索引,下面的SQL就用到了user表主键id。
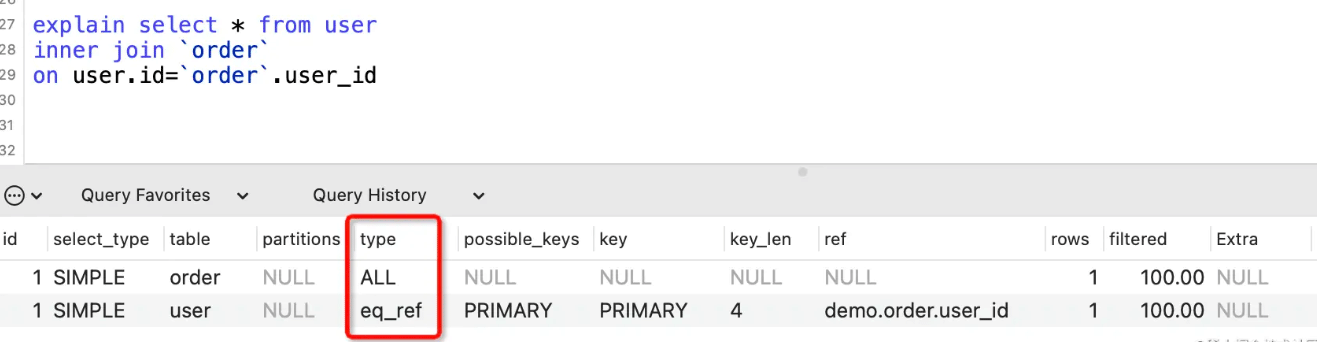
ref
表示使用非唯一性索引进行等值查询。
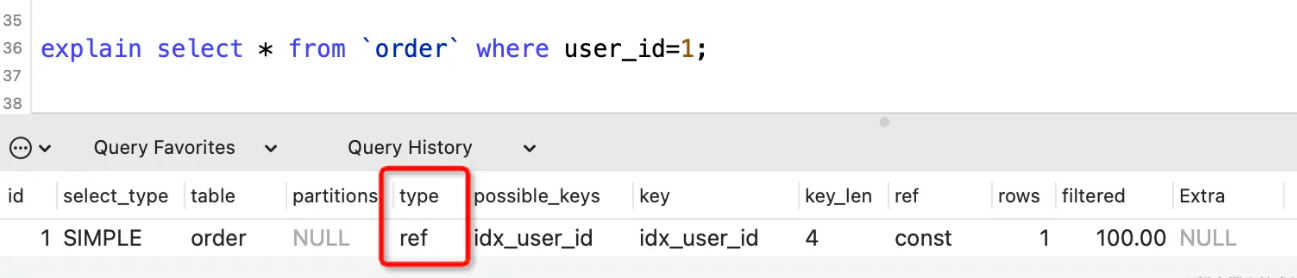
ref_or_null
表示使用非唯一性索引进行等值查询,并且包含了null值的行。

index_merge
表示用到索引合并的优化逻辑,即用到的多个索引。

range
表示用到了索引范围查询。

index
表示使用索引进行全表扫描。

ALL
表示全表扫描,性能最差。

possible_keys列
表示可能用到的索引列,实际查询并不一定能用到。

key列
表示实际查询用到索引列。

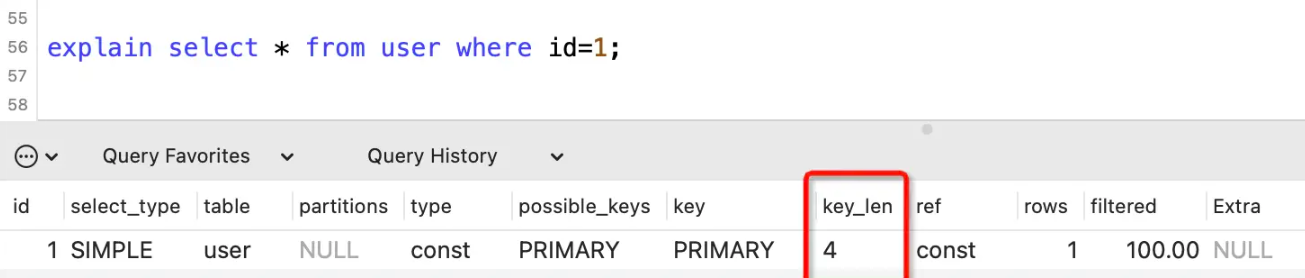
key_len列
表示索引所占的字节数。
每种类型所占的字节数如下:
| 类型 | 占用空间 |
|---|---|
| char(n) | n个字节 |
| varchar(n) | 2个字节存储变长字符串,如果是utf-8,则长度 3n + 2 |
| tinyint | 1个字节 |
| smallint | 2个字节 |
| int | 4个字节 |
| bigint | 8个字节 |
| date | 3个字节 |
| timestamp | 4个字节 |
| datetime | 8个字节 |
| 字段允许为NULL | 额外增加1个字节 |
ref列
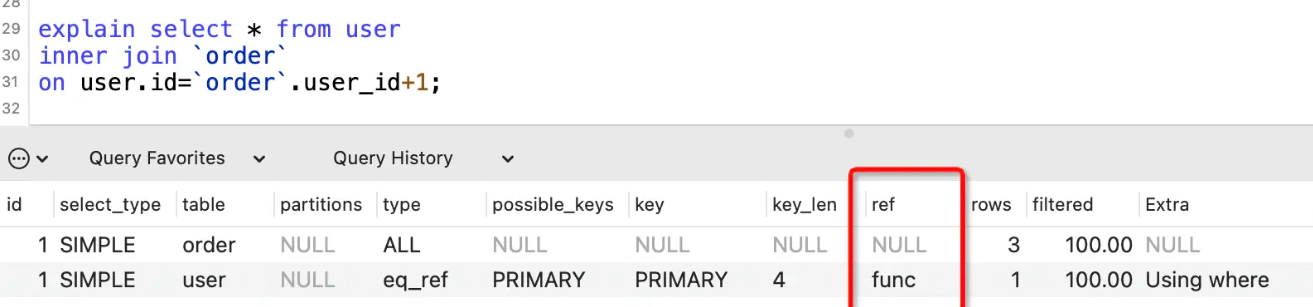
表示where语句或者表连接中与索引比较的参数,常见的有const(常量)、func(函数)、字段名。
如果没用到索引,则显示为NULL:

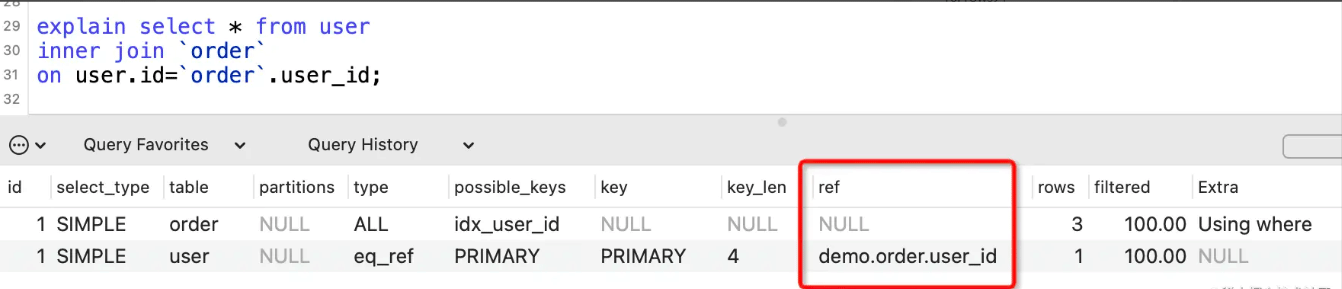
rows列
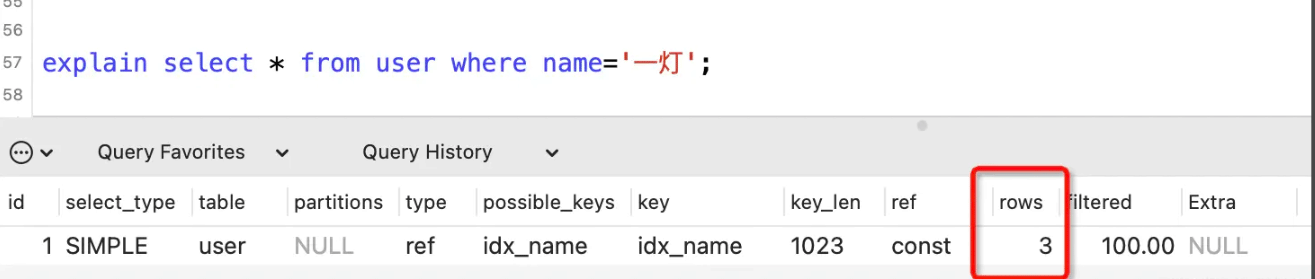
表示执行SQL语句所扫描的行数。
filtered列
表示按条件过滤的表行的百分比。

用来估算与其他表连接时扫描的行数,row x filtered = 252004 x 10% = 25万行
Extra列
表示一些额外的扩展信息,不适合在其他列展示,却又十分重要。
Using where
表示使用了where条件搜索,但没有使用索引。

Using index
表示用到了覆盖索引,即在索引上就查到了所需数据,无需二次回表查询,性能较好。

Using filesort
表示使用了外部排序,即排序字段没有用到索引。

Using temporary
表示用到了临时表,下面的示例中就是用到临时表来存储查询结果。

Using join buffer
表示在进行表关联的时候,没有用到索引,使用了连接缓存区存储临时结果。
下面的示例中user_id在两张表中都没有建索引。

Using index condition
表示用到索引下推的优化特性。

知识点总结
本文详细介绍了Explain使用方式,以及每种参数所代表的含义。无论是工作还是面试,使用Explain优化SQL查询,都是必备的技能,一定要牢记。
SQL查询优化方式图表:

到此这篇关于使用MySQL的Explain执行计划的方法(SQL性能调优)的文章就介绍到这了,更多相关MySQL Explain内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
本文标题为:使用MySQL的Explain执行计划的方法(SQL性能调优)


- redis清除数据 2023-09-13
- MySQL8.0.28安装教程详细图解(windows 64位) 2023-07-26
- Numpy中如何创建矩阵并等间隔抽取数据 2023-07-28
- 搭建单机Redis缓存服务的实现 2023-07-13
- 基于Python制作一个简单的文章搜索工具 2023-07-28
- SQLSERVER调用C#的代码实现 2023-07-29
- Mongodb启动报错完美解决方案:about to fork child process,waiting until server is ready for connections. 2023-07-16
- SQL Server 2022 AlwaysOn新特性之包含可用性组详解 2023-07-29
- Oracle 删除大量表记录操作分析总结 2023-07-23
- 在阿里云CentOS 6.8上安装Redis 2023-09-12








