Python3.7+Yolo3实现识别语音播报功能 一.利用Python调用系统win10的文字转语音 首先下载需要用到的库:pip install pyttsx3 -i https://mirrors.aliyun.com/pypi/simple/ 接下来直接上代码: import win32com.client as win # SpVoice类是支持语音合成(TTS)的核心类.通过SpVoice对象调用
一、利用Python调用系统win10的文字转语音
首先下载需要用到的库:pip install pyttsx3 -i https://mirrors.aliyun.com/pypi/simple/
接下来直接上代码:
import win32com.client as win
# SpVoice类是支持语音合成(TTS)的核心类。通过SpVoice对象调用TTS引擎,从而实现朗读功能
speak = win.Dispatch("SAPI.SpVoice")
# 完成将文本信息转换为语音并按照指定的参数进行朗读。
# 该方法有Text和Flags两个参数,分别指定要朗读的文本和朗读方式(同步或异步等)。
speak.Speak("come on")
speak.Speak("你好")
最后运行代码,就会听到系统传出来的声音,读出了 come on 和 你好。
二、开始使用Yolo识别,利用语音播报返回出来
开始之前我们先得解析出来Yolo3的代码,从而获取到被识别出来的物体标签。
首先我们找到一个coco_classes.txt,发现里面有很多的英文单词,这些就是准备识别匹配的标签了。
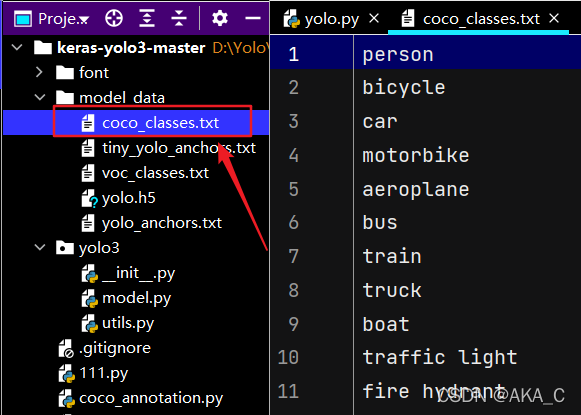
然后我们在找到yolo.py,发现的我们的coco_classes.txt被传入进来了
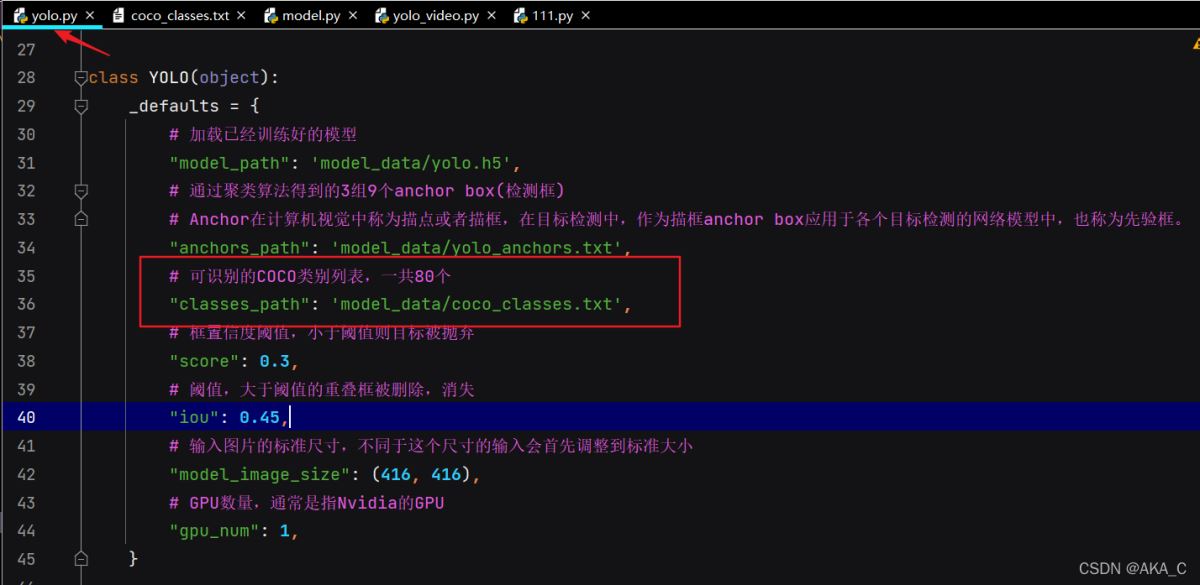
关键的来了,我们通过Ctrl + F 搜索一下classes_path这个Key,发现这几行代码
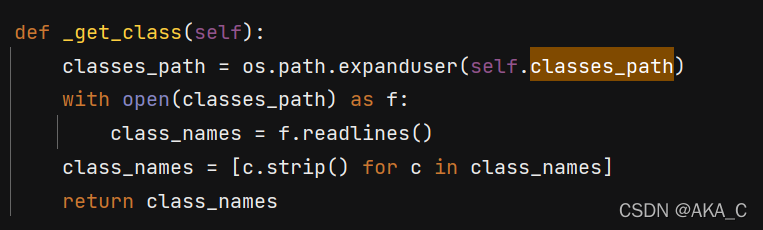
这里就是读取了存放标签的那个文本,进行了处理,并且返回了名字。
最后找到这一行代码,此处代码就是一开始进行识别的时候,我们的控制台打印出来的代码。

运行代码的时候发现,打印的这个label,就是识别出的物体的标签了。
这个时候我们就可以将我们的语音播报的代码添加进行,把label传入进去,就会发现识别出来的物体就会通过语音返回。

Time~
到此这篇关于Python3.7 + Yolo3识别 语音播报的文章就介绍到这了,更多相关Python识别语音内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
本文标题为:Python3.7 + Yolo3实现识别语音播报功能


- windows安装python2.7.12和pycharm2018教程 2023-09-03
- 在centos6.4下安装python3.5 2023-09-04
- python中列表添加元素的几种方式(+、append()、ext 2022-09-02
- Python之路-Python中的线程与进程 2023-09-04
- CentOS7 安装 Python3.6 2023-09-04
- python中defaultdict用法实例详解 2022-10-20
- Python实现将DNA序列存储为tfr文件并读取流程介绍 2022-10-20
- Python Pandas如何获取和修改任意位置的值(at,iat,loc,iloc) 2023-08-04
- python线程池ThreadPoolExecutor与进程池ProcessPoolExecutor 2023-09-04
- Python 保存数据的方法(4种方法) 2023-09-04








