了解MySQL查询语句执行过程(5大组件) 目录 开篇 查询请求的执行流程 MySQL组件定义 连接器 查询缓存 分析器 优化器 逻辑变换 代价优化 执行器 总结 开篇 相信广大程序员朋友经常使用MySQL数据库作为书籍持久化的工具,我们最常使用的就是MySQL中的
目录
- 开篇
- 查询请求的执行流程
- MySQL组件定义
- 连接器
- 查询缓存
- 分析器
- 优化器
- 逻辑变换
- 代价优化
- 执行器
- 总结
开篇
相信广大程序员朋友经常使用MySQL数据库作为书籍持久化的工具,我们最常使用的就是MySQL中的SQL语句,从客户端向MySQL发出一条条指令,然后获取返回的数据结果进行后面的逻辑处理。尽管大家经常使用SQL语句完成工作,你是否关注过其执行的阶段,利用了哪些技术完成?今天,就带大家一起看看MySQL数据库处理SQL请求的全过程。下面将会讲述如下内容:
查询请求在MySQL中的处理流程
MySQL 中处理SQL的组件介绍,包括:
- 连接器
- 查询缓存
- 分析器
- 优化器
- 执行器
查询请求的执行流程
众所周知在MySQL数据库应用中查询请求是使用最多的,假设我们输入代码段1 中的SQL,通过客户端请求MySQL服务器,会得到一个包含user的结果集。但是,其中MySQL的处理过程我们并不了解,那么下面就让我们一起看看在查询请求前后MySQL服务端发生了些什么吧。
Select * from user where userId=1代码段1
如图1 所示,整张图由三部分组成,从上到下分别是客户端(紫色)、MySQL Server层(绿色)、MySQL存储引擎层(黄色)。
- 客户端不言而喻,主要负责与MySQL Server层建立连接,发送查询请求以及接受响应的结果集。
- MySQL Server层,主要包括连接器、查询缓存、分析器、优化器、执行器等。这些组件包含了MySQL的大部分主要功能,例如平时使用最多的存储过程、触发器、视图都在这一层中。 还有一个通用的日志模块 bin log。
- MySQL 存储引擎层,主要负责数据的存储和提取。其支持多个存储引擎,例如:InnoDB、MyISAM等。常用的有InnoDB,它从MySQL 5.5.5版本开始成为了MySQL的默认存储引擎,重要的是InnoDB 引擎包含了自带的日志模块 redo log,这个在后面讲述更新语句的时候会着重提到。
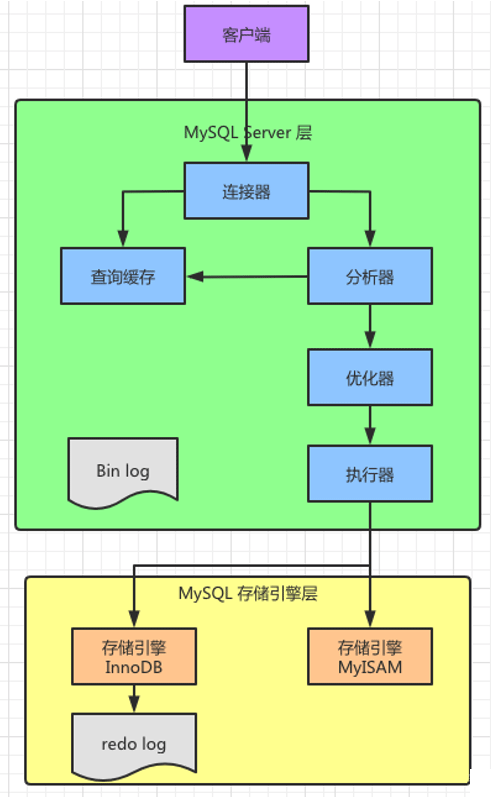
图1 MySQL 查询请求处理流程:
上面介绍了MySQL的组件结构,那么这里将其处理SQL语句的流程简单梳理一遍,之后再对每个组件逐一进行介绍。如图2 所示,在图1 的基础上加上了流程处理的编号,顺着编号来看看MySQL的各各组件是如何处理SQL查询请求的。
- 连接器: 当客户端登陆MySQL的时候,对身份认证和权限判断。
- 查询缓存: 执行查询语句的时候,会先查询缓存(MySQL 8.0 版本后移除)。
- 分析器: 假设在没有命中查询缓存的情况下,SQL请求就会来到分析器。分析器负责明确SQL要完成的功能,以及检查SQL的语法是否正确。
- 优化器: 为SQL提供优化执行的方案。
- 执行器: 将语句分发到对应的存储引擎执行,并返回数据。

图2 SQL 请求执行流程
MySQL组件定义
上面通过一张大图将SQL执行流程进行了梳理,这里将对应的组件进行详细介绍。
连接器
客户端需要通过连接器访问MySQL Server,连接器主要负责身份认证和权限鉴别的工作。也就是负责用户登录数据库的相关认证操作,例如:校验账户密码,权限等。在用户名密码合法的前提下,会在权限表中查询用户对应的权限,并且将该权限分配给用户。在连接完成以后可以通过图3看到连接状态,可以通过命令行“show processlist”生成图3的查询结果。其中“Command”列返回的内容中,“Sleep”表示MySQL相同中对应一个空闲连接。而“Query”表示正在查询的连接。

图3 连接状态
上面提到了连接状态,这里将5种连接状态整理为如下表格,方便大家参考。
|
Command |
含义 |
|
sleep |
线程正在等待客户端发数据 |
|
query |
连接线程正在执行查询 |
|
locked |
线程正在等待表锁的释放 |
|
sorting result |
线程正在对结果进行排序 |
|
sending data |
向请求端返回数据 |
MySQL将连接器中的连接分为长连接和短连接:
- 长连接是指连接成功后,客户端请求一直使用是同一个连接。
- 短连接是指每次执行完SQL请求的操作之后会断开连接,如果再有SQL请求会重新建立连接。
由于短连接会反复创建连接消耗相同资源,因此多数情况下会选择长连接。但是为了保持长连接,会占用系统内存,而这些被占用的内存知道连接断开以后才会释放。
这里提出了两个解决方案:
- 定期断开长连接,每隔一段时间或者执行一个占用内存的大查询以后断开连接,从而释放内存,当查询的时候再重新创建连接。
- MySQL 5.7 或者更高的版本,通过执行 mysql_reset_connection 来重新初始化连接。此过程不会重新建立连接,但是会释放占用的内存,将连接恢复到刚刚创立连接的状态。
查询缓存
在建立与数据库的连接以后就可以执行SQL语句来,不过在执行之前会先查询缓存,其目的是查看是否之前执行过该语句,并且将执行结果按照key-value的形式缓存在内存中了。
Key 是查询的SQL语句,Value 是查询的结果。如果缓存 Key 被命中,就会直接返回给客户端,如果没有命中,就会执行后续的操作,执行完SQL仍旧会把结果缓存起来,方便下一次调用。
MySQL 查询不建议使用缓存,因为会出现这样的场景:如果针对某张表进行更新,针对这张表的查询缓存就会被清空。如果张表不断地被使用(更新、查询),那么查询缓存会频繁地失效,获取查询缓存也失去了意义。不过可以运用在一些修改不频繁的数据表,例如:系统配置、或者修改不频繁的表。缓存的淘汰策略是先进先出,适用于查询远大于修改的情况下, 否则建议使用Redis或者其他做缓存工具。因此大多数情况下不推荐使用查询缓存。MySQL 8.0 版本后删除了查询缓存的功能,官方认为该功能应用场景较少,所以将其删除。
如果你不需要在MySQL中使用查询缓存,也可以将参数query_cache_type设置成 DEMAND,那么默认情况下的执行SQL语句时就不会使用查询缓存了。如果打开了缓存可以通过“show status like 'Qcache%'”命令查看缓存的情况。
如图4 所示,其中几个使用较多的状态值如下:
Qcache_inserts 是否有新的数据添加,每有一条数据添加Value会加一。
Qcache_hits 查询语句是否命中缓存,每有一条语句命中Value会加一。
Qcache_free_memory 缓存空闲大小。
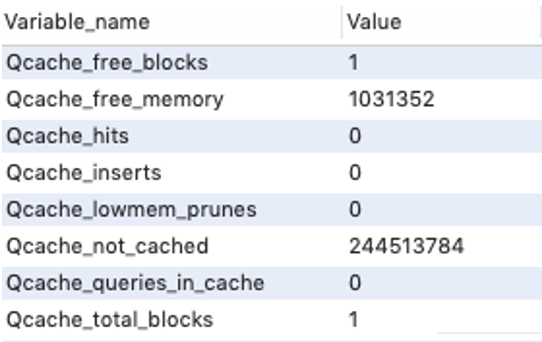
如图4 缓存状态
分析器
如果查询缓存没有命中,那么SQL请求会进入分析器,分析器是用来分辨SQL语句的执行目的,其执行过程大致分为两步:
第一步,词法分析(Lexical scanner)
,主要负责从SQL 语句中提取关键字,比如:查询的表,字段名,查询条件等等。
第二步,语法规则(Grammar rule module)
,主要判断SQL语句是否合乎MySQL的语法。
其实说白了词法分析(Lexical scanner) 就是将整个SQL语句拆分成一个个单词,而语法规则(Grammar rule module)则根据MySQL定义的语法规则生成对应的数据结构,并存储在对象结构当中。其结果供优化器生成执行计划,再调用存储引擎接口执行。来看下面这个例子,假设有这样一个SQL语句“select username from userinfo”。
先通过词法分析,从左到右逐个字符进行解析,获得如表1的四个单词。
|
关键字 |
非关键字 |
关键字 |
非关键字 |
|
select |
username |
from |
userinfo |
表1 语法分析关键字
然后再通过语法规则解析,判断输入的SQL 语句是否满足MySQL语法,并且生成图5的语法树。由SQL语句生成的四个单词中,识别出两个关键字,分别是select 和from。根据MySQL的语法Select 和 from之间对应的是fields 字段,下面应该挂接username;在from后面跟随的是Tables字段,其下挂接的是userinfo。
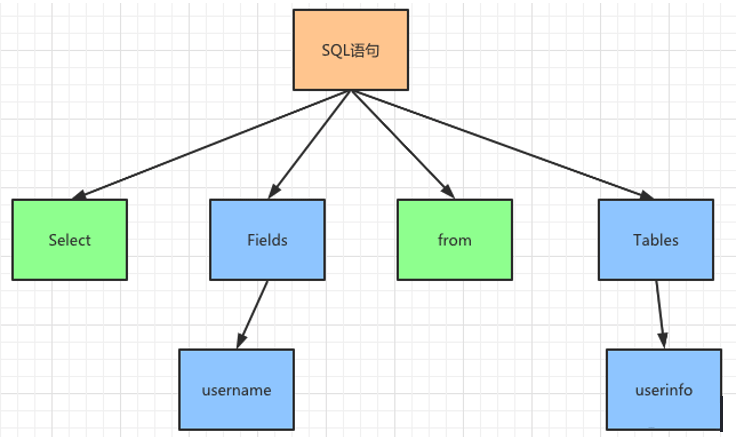
图5 语法规则生成语法树
优化器
优化器的作用是对SQL进行优化,生成最有的执行方案。如图6所示,前面提到的SQL解析器通过语法分析和语法规则生成了SQL语法树。这个语法树作为优化器的输入,而优化器(黄色的部分)包含了逻辑变换和代价优化两部分的内容。在优化完成以后会生成SQL执行计划作为整个优化过程的输出,交给执行器在存储引擎上执行。
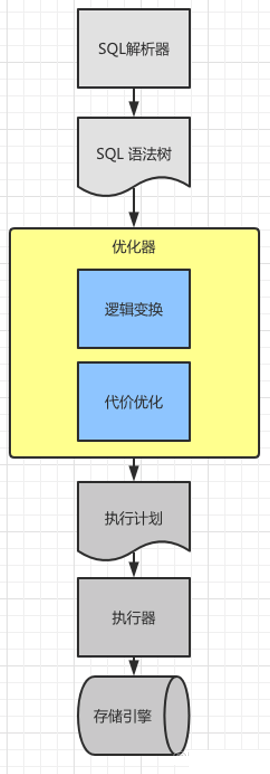
图6 优化器所处的位置
如上图所示,这节的重点在优化器中的逻辑变换和代价优化上。
逻辑变换
逻辑变换也就是在关系代数基础上进行变换,其目的是为了化简,同时保证SQL变化前后的结果一致,也就是逻辑变化并不会带来结果集的变化。
其主要包括以下几个方面:
- 否定消除:针对表达式“和取”或“析取”前面出现“否定”的情况,应将关系条件进行拆分,从而将外层的“NOT”消除。
- 等值常量传递:利用了等值关系的传递特性,为了能够尽早执行“下推”运算。“下推”的基本策略是,始终将过滤表达式尽可能移至靠近数据源的位置。
- 常量表达式计算:对于能立刻计算出结果的表达式,直接计算结果,同时将结果与其他条件尽量提前进行化简。
这样讲概念或许有些抽象,通过图7 来看看逻辑变化如何在SQL中执行的吧。
如图7所示,从上往下共有4个步骤:
- 针对存在的SQL语句,首先通过“否定消除”,去掉条件判断中的“NOT”。语句由原来的“or”转换成“and”,并且大于小于符号进行变号。蓝色部分为修改前的SQL,红色是修改以后的SQL。
- 等值传递,这一步很好理解分别降”t2.a=9” 和”t2.b=5”分别替换掉SQL中对应的值。
- 接下来就是常量表达式计算,将“5+7”计算得到“12”。
- 最后是常量表达式计算后的化简,将”9<=10”化简为”true”带入到最终的SQL表达式中完成优化。
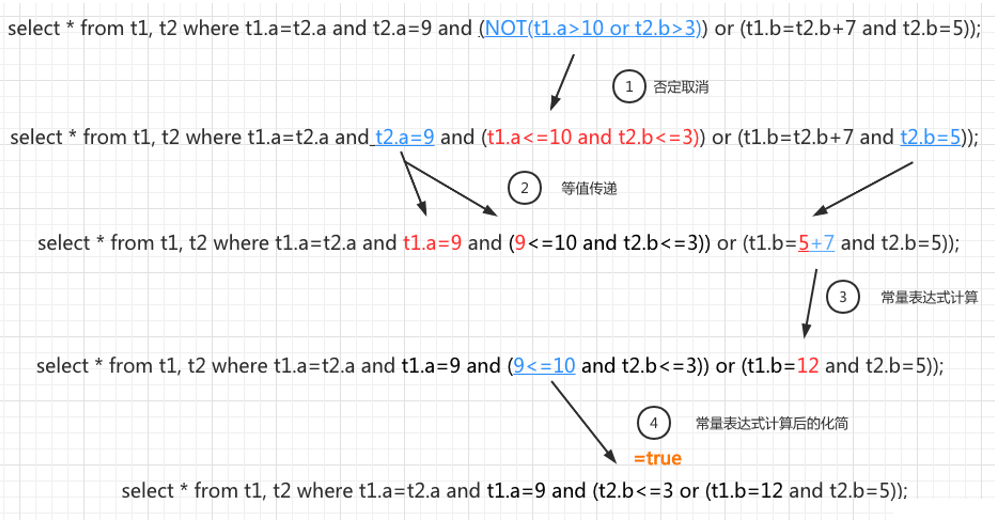
图7 逻辑变换
代价优化
代价优化是用来确定每个表,根据条件是否应用索引,应用哪个索引和确定多表连接的顺序等问题。为了完成代价优化,需要找到一个代价最小的方案。
因此,优化器是通过基于代价的计算方法来决定如何执行查询的(Cost-based Optimization)。
简化的过程如下:
- 赋值操作代价:针对每个数据库操作(创建表、返回数据集)设置对应的代价,这个代价值一般设置为1、0.2之类的值,没有具体的含义就是对操作的代价定义。
- 计算操作数量:将SQL语句中涉及到的操作进行逻辑,并且做计算。说白了就是看这次SQL请求需要做哪些具体的数据库操作。
- 求和操作代价:既然知道SQL由哪些数据库操作组成,同时知道每个操作对应的代价,求和以后就是知道整体SQL执行的代价。
- 选择代价计划:如果说没给SQL执行的操作都是一个计划,那么这些操作的不同组合就会对应不同的计划,这里需要选择整体执行代价最低的操作计划,作为这次执行SQL语句的代价计划,从而达到总代价最低。
这里将配置操作的代价分为MySQL 服务层和MySQL 引擎层,MySQL 服务层主要是定义CPU的代价,而MySQL 引擎层主要定义IO代价。 MySQL 5.7 引入了两个系统表mysql.server_cost和mysql.engine_cost来分别配置这两个层的代价。如下:
MySQL 服务层代价保存在表server_cost中,其具体内容如下:
- row_evaluate_cost (default 0.2) 计算符合条件的行的代价,行数越多,此项代价越大
- memory_temptable_create_cost (default 2.0) 内存临时表的创建代价
- memory_temptable_row_cost (default 0.2) 内存临时表的行代价
- key_compare_cost (default 0.1) 键比较的代价,例如排序
- disk_temptable_create_cost (default 40.0) 内部myisam或innodb临时表的创建代价
- disk_temptable_row_cost (default 1.0) 内部myisam或innodb临时表的行代价
由上可以看出创建临时表的代价是很高的,尤其是内部的myisam或innodb临时表。
MySQL 引擎层代价保存在表engine_cost中,其具体内容如下:
- io_block_read_cost (default 1.0) 从磁盘读数据的代价,对innodb来说,表示从磁盘读一个page的代价
- memory_block_read_cost (default 1.0) 从内存读数据的代价,对innodb来说,表示从buffer pool读一个page的代价
目前io_block_read_cost和memory_block_read_cost默认值均为1,实际生产中建议酌情调大memory_block_read_cost,特别是对普通硬盘的场景。
MySQL会根据SQL查询生成的查询计划中对应的操作从上面两张代价表中查找对应的代价值,并且进行累加形成最终执行SQL计划的代价。再将多种可能的执行计划进行比较,选取最小代价的计划执行。
执行器
当分析器生成查询计划,并且经过优化器以后,就到了执行器。执行器会选择执行计划开始执行,但在执行之前会校验请求用户是否拥有查询的权限,如果没有权限,就会返回错误信息,否则将会去调用MySQL引擎层的接口,执行对应的SQL语句并且返回结果。
例如SQL:
“SELECT * FROM userinfo WHERE username = 'Tom';“假设 “username“ 字段没有设置索引,就会调用存储引擎从第一条开始查,如果碰到了用户名字是” Tom“, 就将结果集返回,没有查找到就查看下一行,重复上一步的操作,直到读完整个表或者找到对应的记录。
需要注意SQL语句的执行顺序并不是按照书写顺序来的,顺序的定义会在分析器中做好,一般是按照如下顺序:
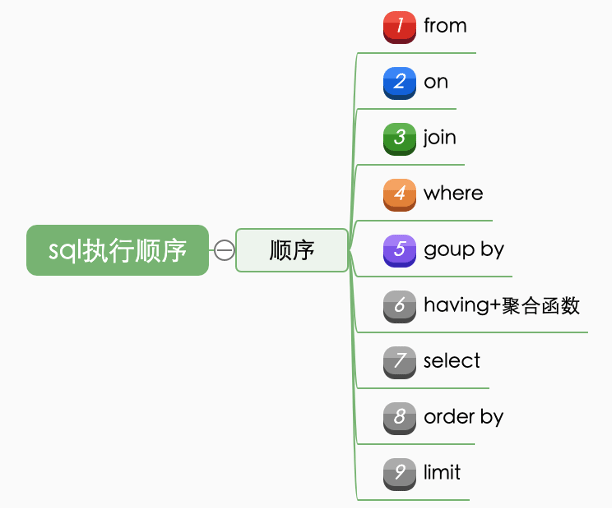
图8 SQL的执行顺序
总结
本文从MySQL中SQL语句的执行过程作为切入点,首先介绍了查询请求的执行流程,其中将MySQL的处理分为MySQL Server层和MySQL存储引擎层。通过介绍SQL语句的流转,引出了后面要介绍的5大组件,他们分别是:连接器、查询缓存、分析器、优化器、执行器。后面的内容中对每个组件进行了详细的介绍。连接器,负责身份认证和权限鉴别;查询缓存,将查询的结果集进行缓存,提高查询效率;分析器,对SQL语句执行语法分析和语法规则,生成语法树和执行计划;优化器,包括逻辑变换和代价优化;执行器,在检查用户权限以后对数据进行逐条查询,整个过程遵守SQL语句的执行顺序。
到此这篇关于了解MySQL查询语句执行过程(5大组件)的文章就介绍到这了,更多相关MySQL查询语句执行内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
本文标题为:了解MySQL查询语句执行过程(5大组件)


- Mongodb启动报错完美解决方案:about to fork child process,waiting until server is ready for connections. 2023-07-16
- 搭建单机Redis缓存服务的实现 2023-07-13
- Numpy中如何创建矩阵并等间隔抽取数据 2023-07-28
- SQL Server 2022 AlwaysOn新特性之包含可用性组详解 2023-07-29
- SQLSERVER调用C#的代码实现 2023-07-29
- Oracle 删除大量表记录操作分析总结 2023-07-23
- MySQL8.0.28安装教程详细图解(windows 64位) 2023-07-26
- 在阿里云CentOS 6.8上安装Redis 2023-09-12
- 基于Python制作一个简单的文章搜索工具 2023-07-28
- redis清除数据 2023-09-13








