这篇“Mysql索引覆盖如何实现”文章的知识点大部分人都不太理解,所以小编给大家总结了以下内容,内容详细,步骤清晰,具有一定的借鉴价值,希望大家阅读完这篇文章能有所收获,下面我们一起来看看这篇“Mysql索引覆盖如何实现”文章吧。
1.什么是覆盖索引
通常情况下,我们创建索引的时候只关注where条件,不过这只是索引优化的一个方向。优秀的索引设计应该纵观整个查询,而不仅仅是where条件部分,还应该关注查询所包含的列。索引确实是一种高效的查找数据方式,但是mysql也可以从索引中直接获取数据,这样就不在需要读数据行了。 覆盖索引(covering index) 指一个查询语句的执行只需要从辅助索引中就可以得到查询记录,而不需要回表,去查询聚集索引中的记录。可以称之为实现了索引覆盖。 在mysql数据库中,如何看出一个sql是否实现了索引覆盖呢?
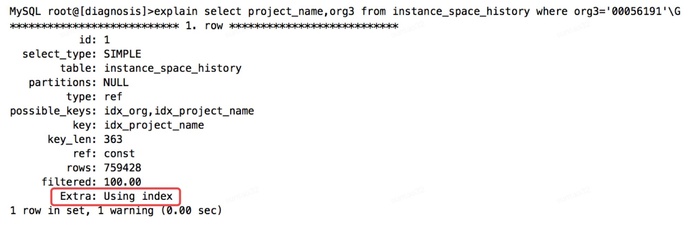
从执行计划看,Extra的信息为using index ,即用到了索引覆盖。
2.覆盖索引为什么快
innodb存储引擎底层实现包括B+树索引和哈希索引,innodb存储引擎默认的索引模型/结构是B+树,所以大部分时候我们使用的都是B+树索引,因为它良好的性能和特性更适合于构建高并发系统。根据索引的存储方式来划分,索引可以分为聚簇索引和非聚簇索引。聚簇索引的特点是叶子节点包含了完整的记录行,而非聚簇索引的叶子节点只有索引字段和主键ID。非聚簇索引中因为不含有完整的数据信息,查找完整的数据记录需要回表,所以一次查询操作实际上要做两次索引查询。而如果所有的索引查询都要经过两次才能查到,那么肯定会引起效率下降,毕竟能少查一次就少查一次。
覆盖索引就实现了从非聚簇索引中直接获取数据,所以效率会提升。
3.SQL优化场景
(1)无where条件
请看下面的sql
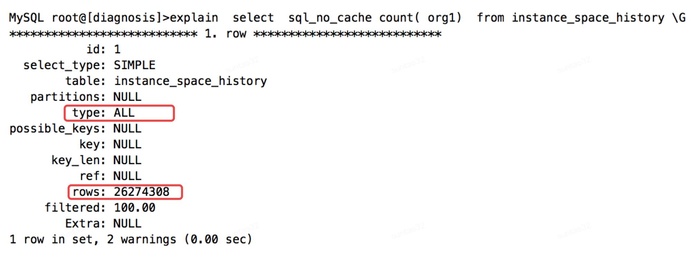
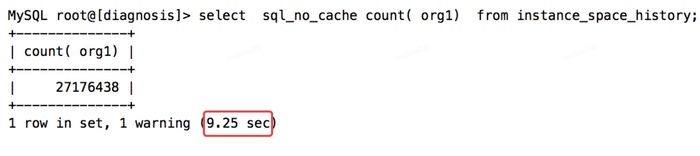
执行计划中,type为ALL,代表进行了全表扫描,扫描行数达到了26274308,所以执行时间为9.25秒,也是正常的。
那么如何优化?优化措施很简单,就是对查询列建立索引。如下,
alter table instance_space_history add index idx_org1(org1); 看添加索引后的执行计划
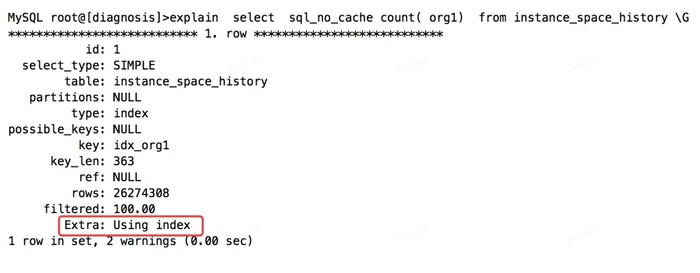
Possible_keys为null,说明没有where条件时优化器无法通过索引检索数据;
但是看extra的信息 Using index,即从索引中获取数据,减少了读取的数据块的数量 。
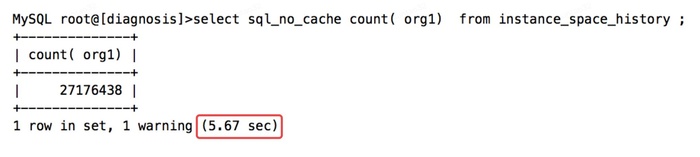
在看实际优化效果,扫描行数没变,但是使用了覆盖索引,查询时间从9.25秒缩短到5.67秒。 思考: 无where条件的查询,可以通过索引来实现索引覆盖查询。但前提条件是,查询返回的字段数足够少,更不用说select *之类的了。毕竟,建立key length过长的索引,始终不是一件好事情。
(2)where条件区分度低
使用区分度极低的字段作为where条件的查询SQL,对于dba或者研发人员优化一直是比较头疼的问题,这里介绍一种思路,就是通过索引覆盖来优化 。 t_material_image是一张8亿多数据的大表,where条件的material_type字段区分度很低,下面是没加任何索引的执行计划和查询时间(7.35秒)。


最容易想到的优化方式,就是给where条件的字段加索引,添加索引语句如下: alter table t_material_image add index idx_material_type (material_type);
再来看执行计划

通过执行计划和测试结果看,的确是有效果的,但是走索引后的查询效率依然不能满足我们期望。 然后试着给material_type,material_id添加联合索引。 alter table t_material_image add index idx_material_id_type (material_type,material_id);


从这个sql的执行计划看,出现Using index,实现了索引覆盖;再看执行时间,性能得到了巨大的提升,居然已经可以跑到0.85s左右了。
思考:
当where条件字段区分度低(过滤性差),且where条件与查询字段总数较少的情况下,使用索引覆盖优化,是个不错的选择。
(3)查询仅选择主键
对于Innodb的辅助索引,它的叶子节点存储的是索引值和指向主键索引的位置,然后需要通过主键在查询表的字段值,所以辅助索引存储了主键的值。如果查询所选择的列只有主键,应该考虑通过索引覆盖优化。 看下面的两个sql,字段 pin 和completion_time有联合索引,where条件差别只有comment_voucher_status = 0,但是执行时间差距巨大(第一个sql0.58s,第二个sql0.2s),为什么呢?是不是很困惑




我们来看执行计划,主要差别体现在extra,第一个sql用到Using index condition,而第二个sql用到Using index,因为pin和completion_time有联合索引,而且查询结果只选择了主键id,所以第二个sql覆盖了所有的where条件字段和查询结果选择字段,故实现了索引覆盖。 思考:
当查询字段只有主键时,更容易实现索引覆盖,因为索引只要覆盖where条件,就可以实现索引覆盖。
以上就是关于“Mysql索引覆盖如何实现”这篇文章的内容,相信大家都有了一定的了解,希望小编分享的内容对大家有帮助,若想了解更多相关的知识内容,请关注***行业资讯频道。










