Mysql数据库面试必备之三大log介绍 目录 一.redo log 重做日志(MySQL 存储引擎 InnoDB 的事务日志) 二.undo log 回滚日志(MySQL 存储引擎 InnoDB 的事务日志) 三.bin log 归档日志(数据库 Server 层二进制逻辑日志.和什么引擎无关) 快,开篇大伙先思考一个问题,MyS
目录
- 一、redo log 重做日志(MySQL 存储引擎 InnoDB 的事务日志)
- 二、undo log 回滚日志(MySQL 存储引擎 InnoDB 的事务日志)
- 三、bin log 归档日志(数据库 Server 层二进制逻辑日志、和什么引擎无关)
快,开篇大伙先思考一个问题,MySQL 是怎么保证数据不丢失的呢?
其实要保证数据不丢失,说白了要具有下面两种能力:
(1)能恢复到任何时间点的状态;
(2)能保证 MySQL 在任何时间段突然宕机重启,已提交的数据不会丢失,未提交完整的数据也会自动回滚;
这不就引出来今天要聊的主题了么,实现第一点需要用 bin log,实现第二点需要用 redo log 和 undo log。
了解三大log之前,我们先看一下Mysql数据更新的流程:
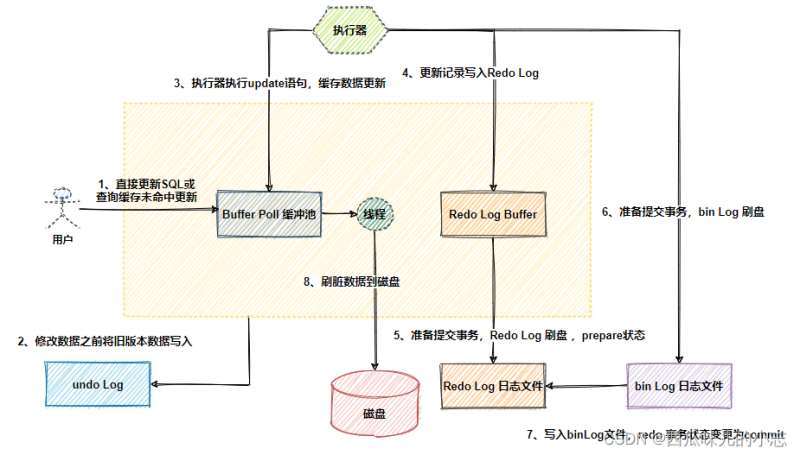
上面这张图包含了 redo log、bin log、undo log 三种日志之间的大致关系,下面进入正题。
一、redo log 重做日志(MySQL 存储引擎 InnoDB 的事务日志)
我们知道 MySQL 数据存在磁盘中,每次读写数据需做磁盘 IO,并发场景下性能差。为此 MySQL 引入缓存 Buffer Pool 做优化。其包含磁盘中部分数据页(page)的映射,来缓解数据库的磁盘压力。
当从数据库读数据时,首先从缓存中读,缓存中没有,则从磁盘读后放入缓存;当向数据库写数据时,先向缓存中写,此时缓存中的数据页数据会变更,该数据页叫脏页,Buffer Pool 中修改完数据后会按照设定的策略再定期刷到磁盘中去,这个过程叫刷脏页。
那么问题来了,如果 Buffer Pool 中修改的数据还没有及时的刷到磁盘,MySQL 宕机重启,就会导致数据丢失,无法保证事务的持久性,怎么办?
redo log 解决了这个问题。就是说数据库在修改数据时,会把更新记录先写到 redo log 中,再去修改 Buffer Pool 中的数据,当提交事务时,调用 fsync 把 redo log 刷入磁盘。至于缓存中更新的数据文件何时刷入磁盘,则由后台线程异步处理。
注意:此时 redo log 的事务状态是 prepare,还未真正提交成功,要等 bin log 日志写入磁盘完成后才会变为 commit,事务才算真正提交成功。
redo log 的写入方式?
redo log 采用大小固定,循环写入的方式,当写满后,会重新从头开始循环写,类似一个环状。这样设计原因是 redo log 记录的是数据页上的修改,如果 Buffer Pool 中数据页已经刷到磁盘,这些记录就失效了,新日志会将这些失效的记录覆盖擦除。
注意:redo log 满了,在擦除之前,要确保这些要被擦除记录都已经刷到磁盘中了。在擦除旧记录释放新空间期间,不能再接收新的更新请求,此时 MySQL 性能会下降。因此高并发情况下,合理调整 redo log 大小很重要。
crash-safe 能力是什么?
Innodb 引擎有 crash-safe 能力,即事务提交过程中任何阶段,MySQL 宕机重启后都能保证事务的完整性,已提交的数据不会丢失。这种能力是通过redo log保证的,MySQL 宕机重启,系统将自动检查 redo log,将修改还未写入磁盘的数据从 redo log 恢复到 MySQL 中。
二、undo log 回滚日志(MySQL 存储引擎 InnoDB 的事务日志)
undo log 记录的是数据修改之前的状态,属于逻辑日志,起到回滚的作用,是保证事务原子性的关键。
举个栗子:假如更新 ID=1 记录的 name 字段,name 原始数据为小王,现改 name 为小张,事务执行 update X set name = 小张 where id =1 语句时,先在 undo log 中记录一条相反逻辑的 update X set name = 小王 where id =1 记录,这样当某些原因导致事务失败,就可借助 undo log 将数据回滚到事务执行前的状态。
那么问题来了:同一个事务的一条记录被多次修改,难道每次都要把数据修改前的状态写 undo log 吗?
不会,因为 undo log 只记录事务开始前数据的原始版本,当再次对这行数据修改时,产生的修改记录会写到 redo log。undo log 负责回滚,redo log负责前滚。
啥是回滚和前滚?
(1)回滚
未提交的事务,即事务未执行 commit。但事务内修改的脏页中,有一部分已刷盘。此时数据库宕机重启,需要回滚来将先前那部分已经刷盘的脏块从磁盘上撤销。
(2)前滚
未完全提交的事务,即事务已经执行 commit,但该事务内修改的脏页中只有一部分数据被刷盘,另一部分还在 buffer pool,此时数据库宕机重启,就要用前滚来将未来得及刷盘的数据从 redo log 中恢复出来并刷盘。
三、bin log 归档日志(数据库 Server 层二进制逻辑日志、和什么引擎无关)
bin log 记录了用户对数据库所有 sql 操作(不包含查询语句,因为这类操作对数据本身没有修改)。之所以可以称为归档日志,是因为它不会像 redo log 那样循环擦除之前的记录,而是会一直记录日志。一个 bin log 文件默认最大容量1G(可通过 max_binlog_size 参数修改),单个日志超过最大值则会新创建一个文件继续写。
注意:日志可能是基于事务来记录的,而事务不应该跨文件记录,如果 binlog 日志文件达到了最大值但刚好事务还没有提交,此时则不会创建新文件记录,而是继续增大日志。因此 max_binlog_size 的值和实际的 binlog 文件大小不一定相等。
经过上述介绍,binlog 主要用就是主从同步和数据库基于时间点的还原。
那么问题来了,可以没有 binlog 吗(有了 redo log 为啥还需要 bin log)?
需要分场景来看:
主从模式下,binlog 是必须的,因为从库的数据同步需要依赖 binlog;
单机模式下,不考虑数据库基于时间点的还原,binlog 就不是必须的,因为有 redo log 就可以保证 crash-safe 能力了;
redo log 的记录修改落盘后,日志会被覆盖掉,无法用于数据恢复等操作,redo log 是 innodb 引擎层实现的,并不是所有引擎都有;
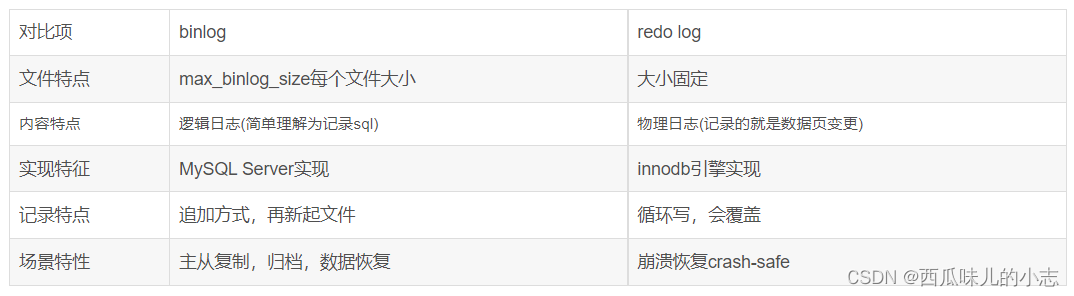
redo log 与 bin log 的区别?
什么是 redo log 两阶段提交,为什么要这么做?
更新内存后引擎层写 redo log 将状态改成 prepare 为提交第一阶段,Server 层写 bin log,将状态改成 commit 为提交第二阶段。 两阶段提交目的是确保 binl og 和 redo log 数据一致性。
如果不是两阶段提交可能会出现什么情况?
1)假设先写 redo log 再写 bin log,即 redo log 没有 prepare 阶段,写完直接置为commit,然后再写 bin log。如果写完 redo log 后还没写完 bin log 数据库宕机了,重启后系统自动用 redo log 恢复,此时会造成磁盘上数据页数据比 bin log 上的记录数据多,数据不一致。
2)假设先写 bin log 再写 redo log,如果写完 bin log 没写完 redo log 数据库宕机了,那么 bin log 上的记录就会比磁盘上数据页的记录多一些,下次用 bin log 恢复数据,恢复后的数据和原来的数据不一致。
描述一下 redo log 容灾恢复过程?
如果 redo log 是完整(commit 状态)的,直接用 redo log 恢复;
如果 redo log 是预提交 prepare 但不是 commit 状态,此时要去判断 binlog 是否完整,如果完整(commit)那就提交 redo log,再用 redo log 恢复,不完整就回滚事务。
到此这篇关于Mysql数据库面试必备之三大log介绍的文章就介绍到这了,更多相关Mysql三大log内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
本文标题为:Mysql数据库面试必备之三大log介绍


- 在阿里云CentOS 6.8上安装Redis 2023-09-12
- Numpy中如何创建矩阵并等间隔抽取数据 2023-07-28
- SQL Server 2022 AlwaysOn新特性之包含可用性组详解 2023-07-29
- Mongodb启动报错完美解决方案:about to fork child process,waiting until server is ready for connections. 2023-07-16
- MySQL8.0.28安装教程详细图解(windows 64位) 2023-07-26
- 搭建单机Redis缓存服务的实现 2023-07-13
- SQLSERVER调用C#的代码实现 2023-07-29
- Oracle 删除大量表记录操作分析总结 2023-07-23
- 基于Python制作一个简单的文章搜索工具 2023-07-28
- redis清除数据 2023-09-13








